Decision Tree
What is decision tree?
Decision Tree is similar like structure to programmers if-else condition. It is nothing but a nested if-else classifier.
Decision Tree is nothing but the set of hyperplanes that are axis-parallel which divides region into multiple classes.
What is Entropy?
- Entropy is the measure of impurity in a set of data.
- It is used to determine best feature to split on at root node.
There are some properties related to Entropy that we need to understand
Let’s Say we have feature Y which belongs to two class categories
Y-i belongs to positive and negative class
- If we get situation where one class dominates to another; like y-positive 99% and y-negative 1% data
OR
- y-positive 0% and y-negative 100% data; then entropy would be near or equal to ZERO.
- If distribution of both y-positive and y-negative are same that is 50–50% respectively, Because the both classes are equally probable; maximum entropy would be ONE (for two class classification) and max entropy for two class classification cannot be > 1.
But what if we have multiclass classification category?
Let’s say Y belongs to multiclass category and Y-i belongs to Y1, Y2, Y3 and so on till Yk.
- So if all the classes are equi-probable then entropy would be maximum.
- If one class, say Y1 is most probable and remaining classes are less probable then entropy would be minimal.
Until now we have seen entropy for categorical situations, but what if my data is real-valued?

- In case of discrete and continuous uniform distribution entropy of 1 would be maximum.

- In case if Let’s say Y1 is less peaked distribution than Y2 (Say normal curve) and Y2 is very peaked; then entropy of Y2 is < entropy of Y1. Because there is less chance that probabilities are equi-probable.
Now let’s see How we can use entropy for other task
Entropy can be used as measure of how balanced dataset is.
- When entropy of dataset tends to or nearby ZERO then dataset is very unbalanced.
- When entropy of dataset tends to nearby ONE then dataset is very balanced.
If we calculate entropy of two features and find that one entropy is higher than others, what does it actually tells us?
Entropy is the measure of uncertainty or randomness or unpredictability.
Does it say that feature with higher entropy has more random values than one with lower entropy?
YES…
Let’s take an example to understand this -
Say we’ve tossed a coin 4 times and we get outcome as {H, T, T, H}
Based on this observation if you guess what will be output of coin toss, then what would be your guess?
Two Heads and Two Tails makes 50% chance for Head and Tail respectively.
Hence we cannot be sure what will be our output of coin toss as it will be random.
But, if we’ve biased coin, which when tossed 4 times, gives the following output {T, T, T, H} .
Here if we’ve to guess the output of coin toss, what would be your guess?
Chances are you go with Tail
and Why?
Because 75% chance is the output is Tail based on sample we have.
In other words, a result is less random in the case of biased coin
then what it was in case of perfect coin
Hence we can say that — Unbiased coin has high entropy; because the uncertainty of value of X is highest possible.
Let’s take an simple example to understand it better -
A simple example of entropy in decision tree can be seen in a coin flip scenario.
Let’s say we flip a coin two times, and both times it lands on heads.
The entropy of this scenario would be 0, as there is no uncertainty or randomness in the result.
On the other hand, if we flip the coin two times and get one head and one tail, the entropy would be 1, as there is maximum uncertainty or randomness in the result.
In decision tree, entropy is used to determine the best feature to split on at the root node by measuring the impurity or randomness in the data.
The goal is to minimize entropy and create more pure or homogeneous subsets of data, leading to more accurate predictions.
What is Information Gain?
Information Gain is the measure of how much information a feature gives about the target variable or class.
Why Information Gain matters?
- Information gain matters in decision tree because it helps determine the feature that best splits the data to build a decision tree.
- The feature with the highest information gain becomes the root node of the tree, and the process is repeated on each subset of the data.
- By maximizing information gain at each split, the decision tree algorithm builds a tree with the most informative features at the root, leading to higher accuracy in predictions.
Let’s understand this with an example —
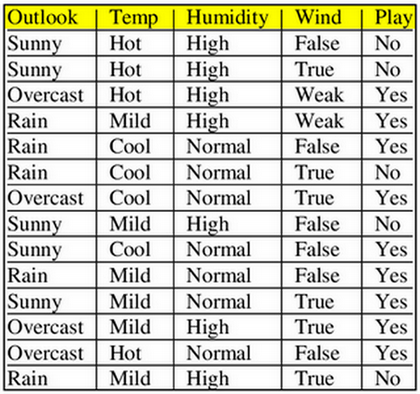
Let’s consider a tennis dataset The goal is to predict whether someone would play tennis or not based on the outlook, temperature, wind and humidity.